
资料来源:
欧姆社学习漫画-漫画机器学习 ((日)荒木雅弘著;喻春燕译.).pdf(渣服务器可能下载有点慢)
Python 基础教程 | 菜鸟教程 (runoob.com)
sklearn — scikit-learn 1.5.1 文档
本文仅是对欧姆社学习漫画-漫画机器学习的补充与总结,不宜当作教程,配合欧姆社学习漫画-漫画机器学习进行阅读
注意机器学习始终都离不开线性代数,这里有了解线性代数的视频
https://www.bilibili.com/video/BV1ys411472E/
Python
环境搭建
最基本的是在官网直接下载安装Welcome to Python.org
集成开发环境
这里只推荐使用PyCharm:适用于数据科学和 Web 开发的 Python IDE (jetbrains.com)
一般下载社区版就好了

安装 PyCharm 中文插件,打开菜单栏 File,选择 Settings,然后选 Plugins,点 Marketplace,搜索 chinese,然后点击 install 安装:

AI 编程助手
可以自动生成代码,提升开发效率
主要是完全免费
直接在插件中搜索Fitten Code安装就可以了
文件结构
新建一个项目
对于大多数情况,解释器类型选择项目venv较适合
在Python中,一个典型项目的文件结构如下
myproject/
├── myenv/
│ ├── bin/
│ ├── include/
│ ├── lib/
│ └── pyvenv.cfg
├── src/
│ ├── main.py
│ └── utils.py
├── tests/
│ └── test_main.py
├── requirements.txt
└── README.md在这个结构中:
myenv/是虚拟环境目录。src/目录包含主要程序文件。tests/目录包含测试文件。requirements.txt文件列出了项目依赖的包。README.md文件包含项目说明。
与本文有关的Python语法
具体可参考Python 基础教程 | 菜鸟教程 (runoob.com)
from…import : 从模块中导入一个指定的部分到当前命名空间中。语法如下:
from modname import name1[, name2[, ... nameN]]zip():将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。
str.format():将字符串内的{xxx:xxx}以特定的格式替换,例如:
print("{0:7s}: {1:6.2f}". format(f, w))0和1代表这个位置要代替的变量的编号
s代表这个变量是字符串
7表示这个变量转化后的最小宽度为7,若不足则向后填充空格
6.2f表示这个变量要精确到小数点后2位且最小宽度为6,若不足则向前填充空格
更多参数参考Python 字符串 format() 菜鸟教程 ,常见的字符串操作 Python 文档
使用GPU提高深度学习效率
参考Tensorflow官网,需要安装以下软件
NVIDIA® GPU 驱动程序 - CUDA® 11.2 要求 450.80.02 或更高版本。
CUDA® 工具包:TensorFlow 支持 CUDA® 11.2(TensorFlow 2.5.0 及更高版本)
(可选)TensorRT 6.0,可缩短用某些模型进行推断的延迟时间并提高吞吐量。
另外TensorFlow与与Cuda更新滞后,最好不要在TensorFlow更新前就直接更新Cuda,否则可能会导致不认显卡
对于Linux,则需要手动声明以下环境变量
export PATH="/pathto/cuda/bin:$PATH"
export LD_LIBRARY_PATH="/pathto/cuda/lib64/:$LD_LIBRARY_PATH"
export XLA_FLAGS=--xla_gpu_cuda_data_dir=/pathto/cuda注意有的环境变量可能写在~/.bashrc没有用,需要手动写脚本或其他方法
回归
在解释变量中找到响应变量
要预测的结果为响应变量,而影响其结果的要素为解释变量
对于解释变量只有一个的情况,找出逼近所有点的直线
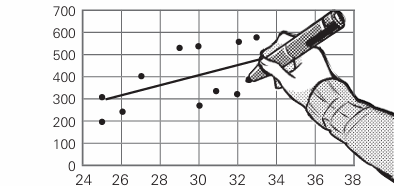
设这样画出的直线的斜率为 w1, 截率为 w0 ,响应变量为 x,解释变量为 y
直线可以这样表示
对于存在多个解释变量的情况
有些解释变量对响应变量的影响大,有些对响应变量的影响小,情况很复杂
假设有两个解释变量 x1、x2,它们权重分别 为 w1、w2,调整整体值的常数为 w0,那么解释变量的加权和为
这个公式表示的是三维空间中的平面。要想预测结果,就要找出逼近这个三维空间中所有点的平面
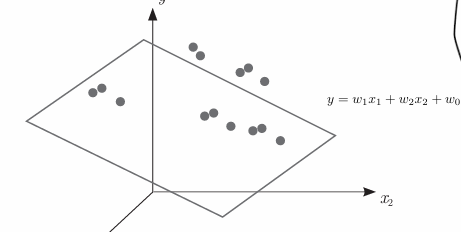
每增加一个解释变量,就增加一个维度
一般来说,如果有 d 个解释变量,就要找出逼近 d+1 维空间中所有点的 d 维超平面(直线)
对这样的情况简单建模,将每个解释变量乘以其重要性即权重,然后求和,便得到了响应变量
这种方法被称为线性回归
求解线性回归函数
将 d 个解释变量表示为 d 维列向量 x,常数 w0 以外的权重用 d 维列向量 w 表示,则超平面可用如下公式表示
T :转置符号
转置:设A为m×n阶矩阵(即m行n列),第i 行j 列的元素是a(i,j),即:
把m×n矩阵A的行换成同序数的列得到一个n×m矩阵,此矩阵叫做A的转置矩阵,记AT
例如矩阵
A = \begin{bmatrix} 1 & 2 & 0\\ a & b & c \end{bmatrix}的转置矩阵为
A^T = \begin{bmatrix} 1 & a\\ 2 & b\\ 0 & c \end{bmatrix}
到目前为止都是用解释变量的加权和表示 y,接下来我们用训练数据中的响应变量表示 y:用cˆ(x) 表示解释变量的加权和。带“ ˆ ”的符号读作“had或估计”表示其根据数据估算出来的,并不一定正确。 由此,式(1)可表示为
那么现在我们的任务就是要最大程度的逼近y,也就是最小化误差
这里定义回归函数的输出cˆ(x ) 与响应变量 y 之差的平方和为回归函数的损失函数,也就是均方误差损失函数。采用最小二乘法学习调整回归函数权重,可以最小化值均方误差。
常用的损失函数包括四种:均方误差MSE,均方根误差RMSE,平方绝对误差MAE,R-squared
这里使用的是均方误差MSE,公式为:
\frac{1}{m}\sum^m_{i=1}(y_i - \hat{y_i})^2
此时w0需要被整理
这里,为式(2)中的 x 追加第 0 维,将其值固定为 1,并为 w 追加第 0 维 w0,也就是
则回归函数就是 d + 1 维向量的内积,可表示为式(3)
那么现在我们的任务就是估算w
式中的系数 w 通过训练数据{(x1, y1), ··· ,(xn, yn)}估算得到。估算的原则是,由式(3) 计算出的输出 cˆ(x) 与响应变量 y 的误差应尽可能小。误差由式(3)中的系数 w 确定,此时损失函数也就是误差可以表示为 E(w)
在此,为了避免难以处理的综合运算,将解释变量表示为矩阵,将响应变量表示为向量。 若将 d 维列向量的解释变量 x 转置后 n 个纵向排列的矩阵表示为 X,响应变量 y 的值排列为 列向量 y,将系数排列为列向量 w,则误差用下式表示 :
当 w 微分后的值为极值 0 即误差的偏导数为0时误差最小,系数计算如下 :
导数是函数的局部性质。一个函数在某一点的导数描述了这个函数在这一点附近的变化率
导数的几何意义就是斜率
在数学中,一个多变量的函数的偏导数,就是它关于其中一个变量的导数而保持其他变量恒定(相对于全导数,在其中所有变量都允许变化)
矩阵的转置和加减乘除一样,也是一种运算,且满足下列运算规律(假设运算都是可行的):
所以误差可以化为
对于其中各矩阵大小为w:n+1×1 , X:m×n+1 , y:m×1
所以wTXTy和wXyT的大小都为1×1也就是同一个数值,所以可以进行合并
现在我们只需要求出误差的偏导数并令其为0就可以得到误差最小的情况
得到最终公式
也就是说,可以通过训练数据分析与上式得出均方误差最小化的权重w。
将w代入式(3)即可求出线性回归函数cˆ(x)。
正则化
对于那些输入微小变化会导致输出发生很大变化的训练数据,用公式就不会产生好效果
简单来说,正则化是一种为了减小测试误差的行为(有时候会增加训练误差)。我们在构造机器学习模型时,最终目的是让模型在面对新数据的时候,可以有很好的表现。当你用比较复杂的模型比如神经网络,去拟合数据时,很容易出现过拟合现象(训练集表现很好,测试集表现较差),这会导致模型的泛化能力下降,这时候,我们就需要使用正则化,降低模型的复杂度。
作为正则化方法,尽可能减少较大系数值的方法被称为 Ridge(岭)回归,尽可能增加 0 系数值的方法被称为 Lasso 回归
简单来说 ,Ridge回归是将引起误差的因素的影响力降低,Lasso回归是将影响小的因素剔除
正则化可通过在误差方程中追加正则项的方法来实现
也就是表示为以下式子
Ridge 回归
Ridge 回归将参数 w 的平方作为正则项
α 为正则项的权重。这项参数越大, 重要性越向正则化效果倾斜 ;这项参数越小,重要性越向性能倾斜
正如 Ridge 回归方程使用最小二乘法求参数,求得微分后值为 0 的 w
Ridge 回归就是使参数值尽量小的正则化
I :单位矩阵
Ridge 为山脊的意思,单位行 列看起来就像山脊,所以有了这个名字。※
Lasso 回归
Lasso 回归将参数 w 的绝对值作为正则项
Lasso 回归的误差评价公式如下
w0 为回归方程的截距,其值对回归方程的泛化能力没有影响,一般不作为正则化对象
α 是正则项的权重, 越大则值为 0 的权重越多
在 Lasso 回归中,通过稀疏非零权重的解释函数,可以找到影响大的因素
Lasso 回归包含了不能在原点处微分的绝对值,无法像最小二乘法那样通过分析求解,因此请使用可微分的二次函数来保持正则项的上限,可以通过反复更新二次函数的参数以减小误差
使用 Python 进行回归
Python 具有简单丰富的机器学习库 scikit-learn,常用于机器学习系统开发,但不能用于深度学习
大多数训练方法都使用scikit-learn进行编程。
先加载要使用的库。 scikit-learn 附带一些试用数据,可以将它们加载到数据集(datasets)包中。至于回归,可以使用线性回归、Ridge 回归 和 Lasso 回归。
from sklearn.datasets import load_diabetes
from sklearn.linear_model import LinearRegression, Ridge, Lasso对于训练数据,这里使用包含10个糖尿病相关条件的糖尿病数据集, 如年龄、性别、血压和血糖
使用以下代码创建的实例diabetes的data属性是一个矩阵,其中转置的特征向量在列方向上排列,而target属性是作为列向量输入的此疾病的定量测量
diabetes = load_diabetes()
X = diabetes.data
y = diabetes.target可以将实例diabetes的DESCR属性显示为print(diabetes.DESCR),以查看糖尿病数据的详细信息
现在创建一个学习实例。
lr1 = LinearRegression()对此实例,将特征向量集X和答案信息y作为参数,调用fit方法进行学习。
lr1.fit(X, y)有了线性回归方程后,将要预测的数据(10维向量x)作为参数,调用 predict 方法,输出预测值,示例:
x = [[5.1,3.5,1.4,0.2,5.1,0.4,0.5,8.4,2.1,5.1]]
print(lr1.predict(x))在这个实例中会输出对此疾病的定量测量
接下来,我们看看正则化效果。下面显示刚刚学习的线性回归方程的系数及其平方和。
print("Linear Regression")
for f, w in zip(diabetes.feature_names, lr1.coef_) :
print("{0:7s}: {1:6.2f}". format(f, w))
print("coef = {0:4.2f}".format(sum(lr1.coef_**2)))lr1.coef_储存着计算出的各模型系数
diabetes.feature_names储存着各系数的标签(如年龄,性别)
接着,使用Ridge回归尝试相同的过程。数据已经在X和y中,我们可以从创建一个用于学习的实例开始。 此时,如果要指定任何参数, 则以“参数名称=值”的格式作为实例参数传递。 在此,将正则项的权重α设置为10.0。
lr2 = Ridge(alpha=10.0)
lr2.fit(X, y)
x = [[5.1,3.5,1.4,0.2]]
print(lr2.predict(x))
print("Ridge")
for f, w in zip(diabetes.feature_names, lr2.coef_) :
print("{0:7s}: {1:6.2f}". format(f, w))
print("coef = {0:4.2f}".format(sum(lr2.coef_**2)))由系数的平方和可知,总值很小。再接下来是Lasso回归。如果将正则项的权重α设置为2.0,则可以清楚地看到某些系数为0。
lr3 = Lasso(alpha=2.0)
lr3.fit(X, y)
x = [[5.1,3.5,1.4,0.2]]
print(lr2.predict(x))
print("Lasso")
for f, w in zip(diabetes.feature_names, lr3.coef_) :
print("{0:7s}: {1:6.2f}". format(f, w))
print("coef = {0:4.2f}".format(sum(lr3.coef_**2)))分类
在机器学习中,分类是指根据一系列特征将实例数据划分到预先定义的类别或者标签的监督学习任务。具体而言,分类算法可以将输入数据映射到不同的类别,例如将电子邮件分类为“垃圾邮件”或“非垃圾邮件”,或将图像分类为“猫”或“狗”。
数据整理
在数据有缺失的情况下,勉强进行机器学习会对结果产生不良影响。
有大量数据时,可以把有缺失项的数据扔掉, 但是对于一些宝贵数据,就要考虑如何有效利用了
较安全的方法是, 用特征的平均值来填补缺失
但是在数据量小且混有异常值的情况下, 平均值就不一定合适了
为了不受异常值的影响,也有使用中位值或最频值而不是平均值的方法
无论如何要有意识地整理数据,因为特定值数据的增加可能会导致数据分布扭曲


二值分类
二值分类就是简单的把数据分成两类
假设输入仅以数值为元素的向量
如果输入向量是二维的,训练数据就是一个平面上的点的集合
对应类别的值分别用白圈和黑圈表示
和回归时一样,找出能把白圈和黑圈分开的直线
也就是说,可以把分类作为回归的延伸来考虑。
逻辑分类
逻辑分类是指以输入的加权和为基础,求出正例时输出接近1的值,负例时输出接近0的值的函数
针对二值分类问题中的特征向量
考虑各特征的加权和
调整权重,使得正例时输出接近1的值,负例时输出接近0的值
也就是说,要使回归方程的输出正例时为1、 负例时为0,调整权重即可。但是,这样无法 对原点x=0进行判定,所以添加新参数——常数w0
这里,wTx为矢量w与矢量x的内积,其定义为由对应维度要素的乘积之和
那么, g^(x)=0表示的便是d维超平面。
因为那个平面是0,所以平面正面是正例空间,反面就是负例空间
平面上还有些点不能判定为任何类别
这样在特征空间分割类别的面被称为分类面
各个点的判断准确性反映在离分类面的距离上
但这样一来中x的值可能会非常大或非常小,很难与概率对应
为了使得g^(x)的输出范围在0~1,要向属于正例的x输入接近1的值,属于负例的x的输入接近0的值
进行变换后与后验概率对应
在得到结果信息后重新修正的概率称为后验概率
这个式子描述了x正例的概率
则x成为负例的概率是
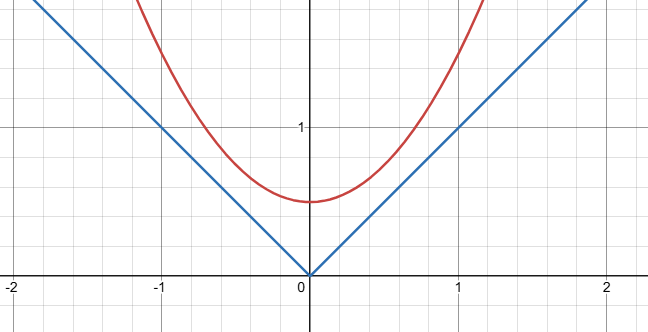
该公式的图表是这样的
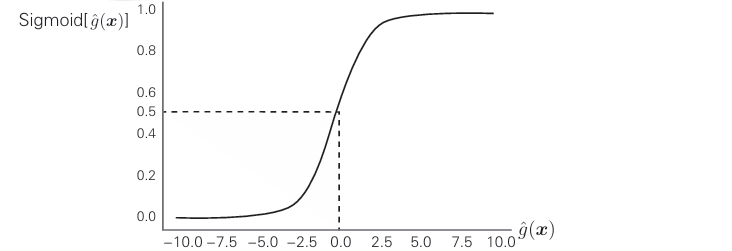
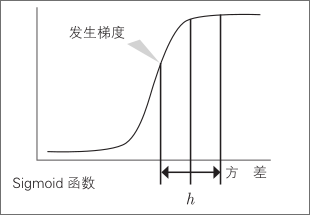
如图所示,无论 g^(x)取何值,公式的值都在0~1,这被称为Sigmoid函数
当 g^(x) =0时,公式的值为0.5
求解逻辑分类回归函数
逻辑分类器可以看作以权重w为参数的概率模型。
简洁起见,后续的w包含w0
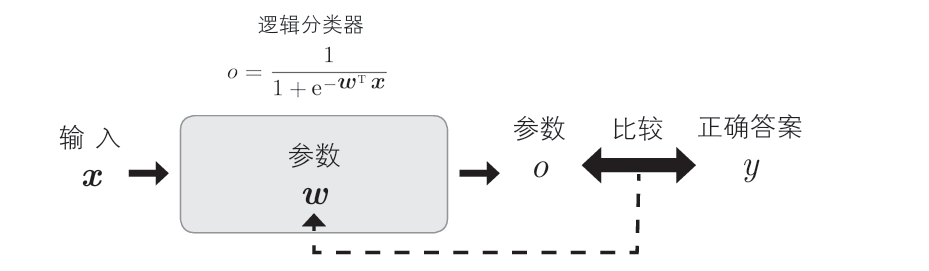
在该模型中,训练数据D的输入为xi ,输出为oi ,期望输出是正确信息yi 。假定其为二值分类问题, 正例时yi = 1,负例时yi = 0。
将每一个样本发生的概率相乘,就是这个合成在一起得到的合事件发生的总概率(利用概率中的乘法公式),即为似然函数,
构建的模型在何种程度能很好地训练数据称为似然,可以利用下式评价。其中,∏是表示乘积的符号。
其中o^{y_i}_i(1-o_i)^{(1-y_i)}表示第i行数据在正例 (yi=1) 时为oi 、负例 (yi=0) 时为1-oi,也就 是说,为了使得正例时的输出oi接近1,负例时的输出oi 接近0,要调整权重w,使所有数据的乘积 P(D|w)变大。
求最大似然值时,按对数似然处理,以便计算
为了使最优化问题可视化,将负对数似然定义为误差函数E(w)之后考虑误差函数的最小化问题。
将其微分求得极值w。由于模型为逻辑分类器,故其输出由Sigmoid函数给出
Sigmoid函数的微分如下:
模型的输出是权重w的函数,改变w时误差也会变化。对此,可以通过最陡梯度法寻求解决方案。
最陡梯度法是将参数一点一点地向想要最小化的函数的梯度方向移动,然后收敛到最优解的方法。
在这种情况下, 参数w会朝误差E(w)的梯度方向一点点移动。如果用学习率η表示这 个“一点点”的量,则最陡梯度法的权重更新可表达为下式:
并且,梯度方向上误差E(w)的计算如下:
因此,权重更新式如下所示:
最陡梯度法在权重更新量低于预定值时结束。
将得到的w带入g^(x)即可求得逻辑分类回归函数
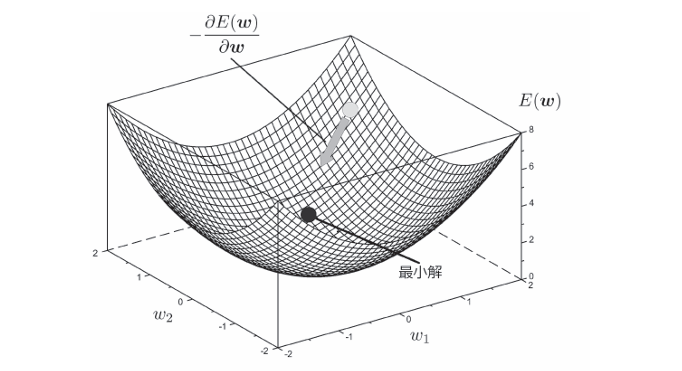
根据全部训练数据D来计算梯度的方法被称为批量梯度下降法。把D分割成适当的大小,以分割后的单位计算梯度的方法被称为小批量梯度下降法。从D中随机选择一个数据, 根据那个数据计算梯度的方法被称为随机梯度下降法。
决策树分类
在决策树上,分类决策点用节点表示,分类结果用叶子表示
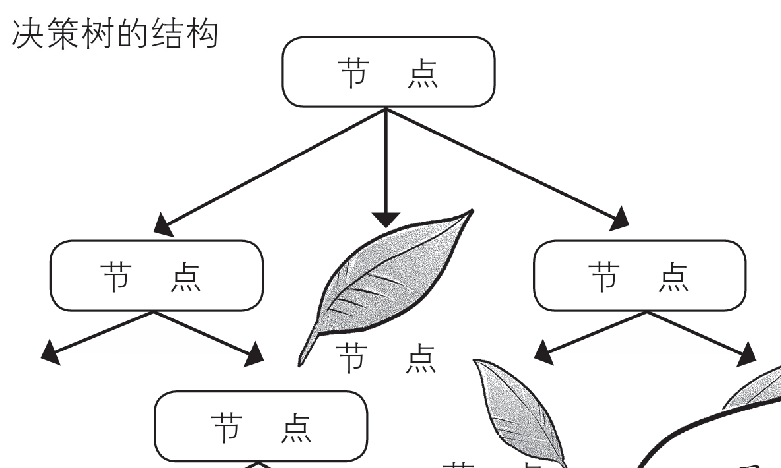
用AND条件将正例的叶子到节点的分歧值组合起来,再加上OR条件,就可以得到等效逻辑表达式
从人的角度来看,利用树状结构来理解学习结果比较容易,所以这种表达方式更受欢迎
创建决策树最基本的算法是ID3算法
这里以高尔夫数据为例
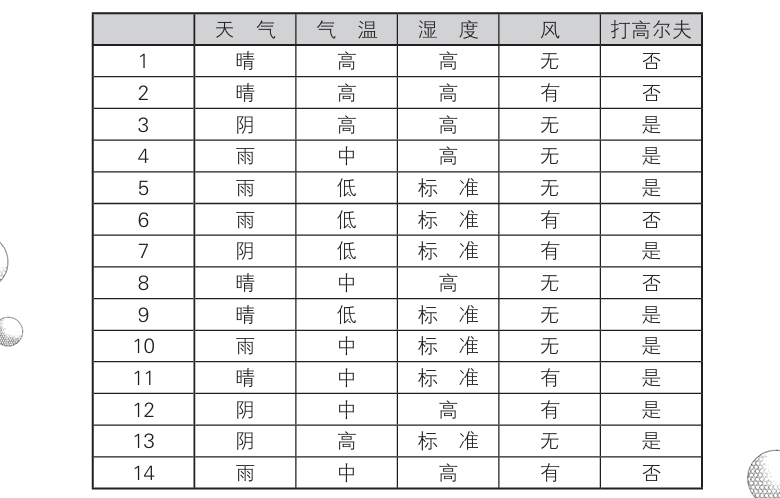
问题是在某一气象条件下, 猜猜那个人是否打高尔夫球
提问一次可以得到一个特征值, 我想尽量用最少次数的提问来得到答案
最好的方案就是先问天气
例如如果回答晴,则数据如下
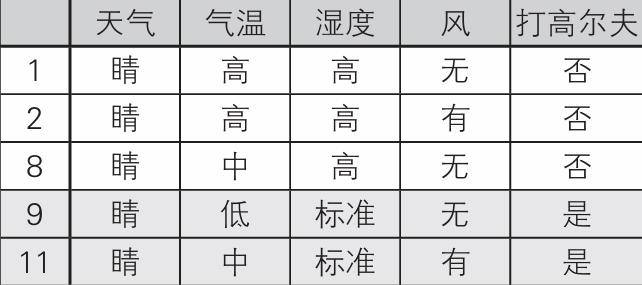
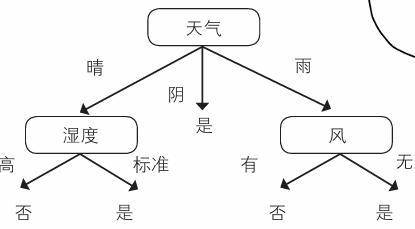
之后问一下湿度,“标准”的回答为“是”
那么, 汇总结果后可以制作出如下决策树
决策树算法
如何提出高效率的问题?
关键就是信息熵与信息量
信息熵,指的是某个数据集中出现 “是”或“否”的不确定性程度
最难确定的是“是”和“否” 的可能性各一半的时候,最容易确定的是全部为“是” 或者全部为“否”的时候,也就是所有的数据集同属 一个类别的时候
信息量是指从某个数据集中得出某个结果(是或否)而得到的信息的量
物以稀为贵,信息也是一样,可以通过取概率的倒数来计算,发生概率高的事件时,信息量小,发生概率低的事情时,信息量大
如果计算该倒数的底为2的对数, 可以得到用二进制表示这个信息所需的位数,二进制数对应电脑内部处理的位数,也就是单位:比特
举个例子,我们听说一个男生的妹妹怀孕并不奇怪,但如果这个男生说他自己要当爸爸了,这个信息量就大了。
信息熵可以通过各类别信息量相对于所有类别数据量的比例的加权和计算,用公式表示如下:
对于分类后的数据集,也可以用和上面类似的公式来求信息熵
将信息熵的减小量定义为信息增益,选择该值最大的问题即可缩小答案范围
计算高尔夫数据的信息熵和信息增益:
原数据D的信息熵为9个“是”和5个“否”,信息熵的计算如下
接下来,计算晴、阴、雨等各种天气数据的信息熵:
将这些值乘以数据量权重,以确定分类的数据集的信息熵:
用原数据的信息熵减去分类后数据的信息熵,可以得到根据提问得到的信息量,也就是信息增益:
用同样的方法,求出针对其他特征提问的信息增益。
因此,把天气作为第一个问题进行数据分类,可以最大限度地减小信息熵,获得信息增益。然后,使用除天气以外的特征,对分类后数据重复同样的步骤。
像这样用数值可识别出效率高的提问
对于数据集的信息熵的计算,也有以下式计算的基尼系数代替信息熵的情况:
G_{ini}(D)=1-P^2_是-P^2_否
为什么要追求最短的假设呢?
这里采用的是“奥卡姆剃刀”定律:如无必要,勿增实体。 它基于“选择合适数据的最简单假设”
如果是长假设,可以偶然解释训练数据,相反,如果是很短的假设,能够偶然解释数据的概率就低了
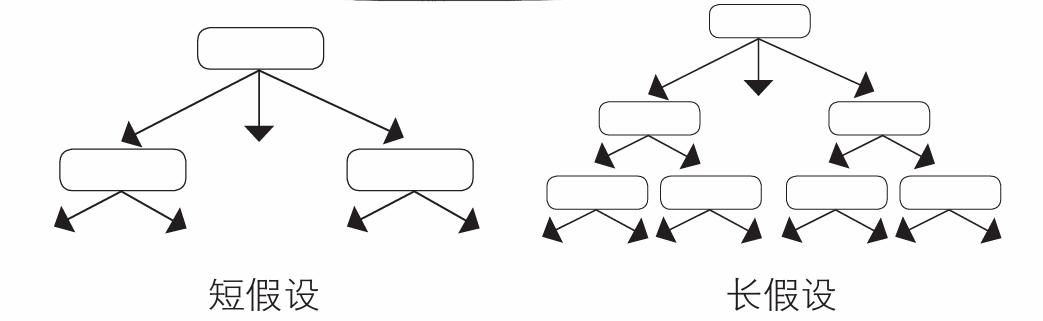
一般情况下,如果按照这个方针学习到最后一个例子都没有错误,就创建决策树
那棵决策树容易过于适应训练数据而导致过学习(过拟合)
模型在验证数据上的准确率会在经过多个周期的训练后达到峰值,然后便停滞不前或开始下降。
换句话说,模型会对训练数据过拟合。学习如何处理过拟合很重要。尽管模型通常可以在训练集上达到很高的准确率,但我们真正想要的是开发出能很好地泛化到测试集(或之前未见过的数据)的模型。
过拟合的反面是欠拟合。当在测试数据上仍有改进空间时就会发生欠拟合。出现这种情况的原因有很多:模型不够强大、过度正则化,或者只是训练时间不够长。这种情况意味着网络尚未学习训练数据中的相关模式。
因此,如果你可以用一棵小树来解释训练数据, 那么该决策树就可以使用
如果能用ID3算法在小树上解释训练数据,偶然的概率会低很多。也就是说,没有偶然,而是必然
应对过学习,有从一开始就限定树深度的方法, 也有完全学习后进行修剪的方法
到目前为止,我们讨论了类别特征的情况。对于数值特征, 把连续值的数值特征分成几个组进行离散化处理,就可以进行决策树的学习了
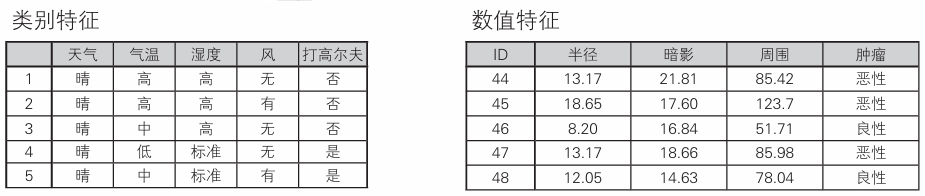
要找到信息熵最小的修剪方法,不在同一个分类里修剪
寻找分类的分界点,就是下图中虚线指示的地方。分界点的值便是前后的值的平均值
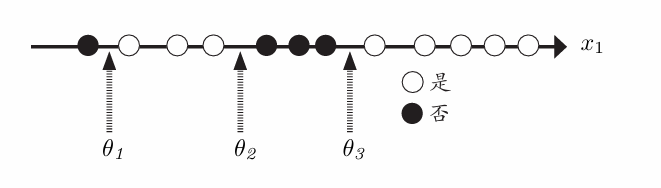
选择这些数据中信息增益最大的地方。如果像类别特征那样进行计算,则阈值θ3处是信息增益最大的分界点
使用Python进行分类
用逻辑分类和决策树创建模型。
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier数据使用判断肿瘤恶性/良性的breast_cancer。
breast_cancer = load_breast_cancer()
X = breast_cancer.data
y = breast_cancer.target在scikit-learn 中,回归也好,分类也好,基本上都是先制作分类实例, 然后用fit方法学习,顺序是一样的。首先是逻辑分类。
clf1 = LogisticRegression(max_iter=3000)
clf1.fit(X,y)max_iter代表最大迭代次数,该值较小时会有警告,可能会对结果准确性有影响,但对代码运行没有影响
和回归时相同,先求解系数。
for f, w in zip(breast_cancer.feature_names, clf1.coef_[0]) :
print("{0:<23}: {1:6.2f}". format(f, w))几个系数为正的大值,参与了正例的判定。相反,系数为负的大值参与了负例的判定。接下来是采用相同的方法创建决策树。
clf2 = DecisionTreeClassifier(max_depth=2)
clf2.fit(X,y)max_depth代表决策树的最大深度
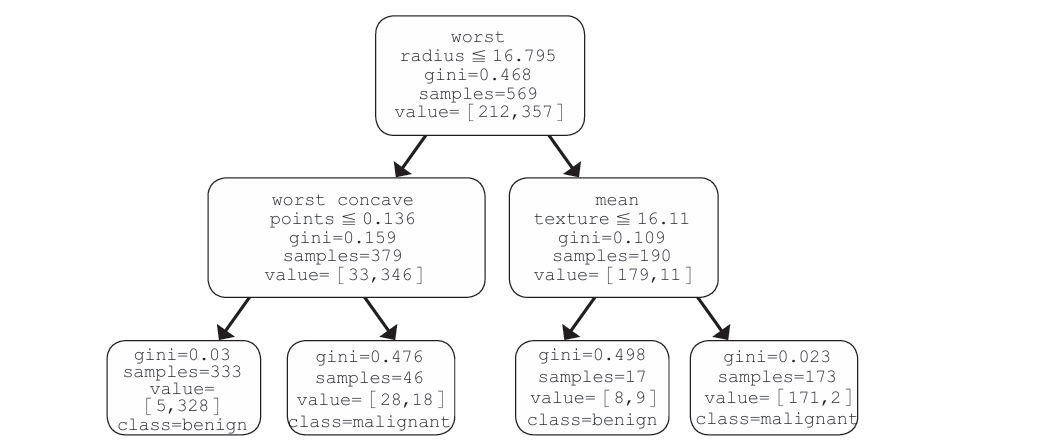
sklearn中的决策树算法是使用的基于ID3算法优化而来的CART
内部有这样的树。首先根据肿瘤半径的平均值(radius)是小于还是大于 16.795分类:小于等于时,如果凹点数平均值(concave points)小于等于0.136,则判断为良性;如果比0.136大,则判断为恶性。另一方面, 当肿瘤半径的平均值大于16.795时,如果暗影值的标准偏差(texture) 小于等于16.11,则判断为良性;如果大于16.11,则判断为恶性。
现在用两种分类方式用示例数据来试试预测吧
test_data = [[17.99,12.38,122.8,1001,0.1184,0.4776,0.3001,0.1471,0.2419,0.07871,1.095,0.9053,9.589,153.4,0.006399,0.04904,0.05373,0.01587,0.03003,0.006193,26.38,17.33,154.6,2019,0.1622,0.6656,0.7119,0.2654,0.4601,0.1189]]
print("Prediction for test data:", clf1.predict(test_data))
print("Prediction for test data:", clf2.predict(test_data))可以看到两种分类方式得到的结果不一定相同,可以尝试调整决策树深度或最大迭代次数来改变准确性
结果评价
机器学习的结果要用不同于训练数据的测试数据进行评价,否则就没有意义
分类器的准确率是针对训练数据的
一般来说,在训练数据中的准确率再高也没什么用
例如,在决策树学习中,如果对树的大小没有限制,那么对于相同的特征向量,只要没有与不同分类信息冲突的数据理论上对于训练数据可以实现 100% 准确率
这样的系统很有可能过度适应训练数据,对于新数据经常会产生识别错误
评价的方法
要掌握未知数据的性能,研究未知数据性能的最简单方法是将手中的数据划分为训练数据和测试数据
数据分割这种数据评价方法在训练时一般不用,而是在计算准确率时使用。那样就能再现未知数据的状况
这个数据分割方法有这样的问题,当全部数据本身的数据量不足时,进一步减小数据量作为训练数据,可能会导致学习性能陡降
也就是说没有足够数量的数据这个方法是不行的
无论是训练还是评价,只有具备足够可靠量的数据时才能使用此方法
并且我们也存在影响训练结果的超参数,例如,线性回归中的正则项的权重和决策树深度等
调查训练中被给予的超参数的值是否妥当的行为被称为验证
如果在验证中使用了测试数据,就不能把测试用数据看作未知数据了
因此,利用分割训练法评价性能的时候,应该将原始数据分割为训练数据、验证数据和测试数据三类
数据量不足时,可以使用交叉验证法。
把数据划分成训练数据和测试数据的方法类似于数据分割法,区别在于把所有数据都用作测试数据
如图所示,对数据进行分割。数据分割数也被称为交叉数。出于交叉数的考虑,10-folder交叉验证法较常用
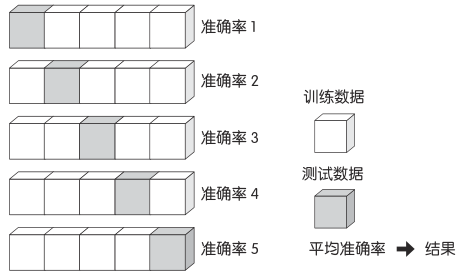
10-folder 交叉验证法也叫十折交叉验证,是指将数据集分成十份,轮流将其中9份作为训练数据,1份作为测试数据,进行试验。每次试验都会得出相应的正确率(或差错率)。10次的结果的正确率(或差错率)的平均值作为对算法精度的估计。
对于 10-folder 交叉验证法,90% 的数据可以用于训练,且所有数据都可以用于测试,所以可以用接近未知数据分布的数据来评价接近实现学习性能上限的系统
每次只用一个样本做测试集的方法叫作留一法
使用交叉验证法时,交叉数 m 越多,测试性能越好,但是很花时间,毕竟每交叉验证一次就要训练一次
交叉验证法原本是数据量不大的时候使用的测试方法,测试只需要进行一次,所以应该尽量做出可靠的测试。若采用留一法,也可以将分割后的样本进行多次交叉验证
计算准确率、精确率、召回率、F 值
粗略的评价对象是准确率,旨在评价数据中分类正确的样本数与样本总数之比
但我们需要更具体地评价分类器性能的方法
简单起见,考虑二分类问题的评价方法
根据是不是有病、是不是垃圾邮件的问题,将符合设定的训练数据称为正例(Positive),不符合设定的数据称为负例(Negative)
因此正确答案有正例和负例两种,分类器的输出也有正和负两种,组合起来就是四种
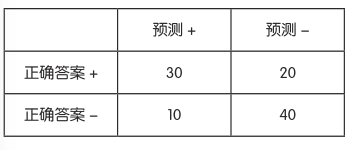
正确答案 + 为正例,正确答案 - 为负例,将分类器判定为正的数据用预测 + 表示,判定为负的数据用预测 - 来表示,如上表所示
这就叫混淆矩阵。数值是临时设置的,所以不要在意。
这里,对角的数据之和就是正确答案数,非对角的数据之和便是预测答案数
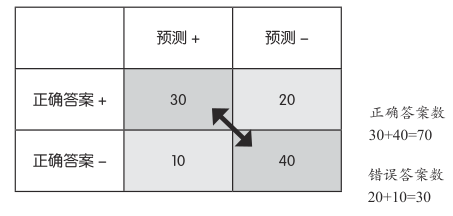
例如,“正确答案 +”行的数值在 50 个正例中,表示分类器正确判定的有 30 个,错误判定的有 20 个
从此表得到的最简单的评价指标是分类器判定的正确答案数除以所有数据的正确答案数,也就是用正确答案数除以全部数据量
该值被称为准确率
乍看之下这个评价似乎很充分,但对机器学习的评价不能止步于此
例如,特定疾病的诊断,未患病者比患病者多得多的情况,和正例相比,负例有大量数据
例如,1000 人中只有 1 人生病,假如使用全部判定为负例的随机分类器,准确率为0.999
为了避免这种状况发生,有必要用各种指标对机器学习的结果进行评价
在此之前,我们先给混淆矩阵的各个元素进行命名
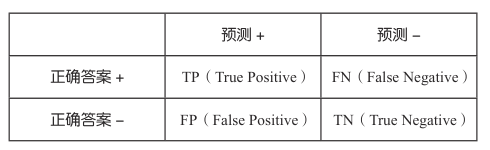
例如,左上角的元素相对于正例,分类器判定为正(Positive),因为预测正确,所以叫作真正类(True Positive)。在以后的公式中,用TP表示True Positive事例数
那么 False Negative 表示错误(False)判定为负(Negative )的假负类
因此,根据这张表,准确率 Accuracy 可以定义为 :
下一个指标为精确率(Precision),它表示分类器判定为正确的可靠性
例如,患者被判定患了某种疾病的时候,由精确率可以知道结果有多可靠
可以理解为在分类器判断为正的情况下是正例的概率
识别器正确判定为正的样本数与分类器预测为正的样本总数之比为精确率
召回率(Recall)是正确判定正例的指标。例如,根据召回率就可以知道在对象数据中患病者能够被正确检出的概率
可以理解为在已经是正例的情况下能被正确预测的概率
用分类器正确判定为正的样本数除以正例数,便得到了召回率
精确率和召回率之间存在着某种对立的关系
例如,对于是否患病的情况,只有在已知自己患有某种疾病的情况下,正确输出的分类器的精确率才会变高
但是那样的话症状轻微的患者就被漏掉了,也就是召回率变低了
相反,如果优先实现高召回率,稍微有点问题分类器就输出正,虽然漏掉患者的情况会变少,但会使很多没有患病的人接受精密检查
因此,将综合判断精确率和召回率的指标定义为 F 值(也叫f1分数)
有三个类别时,创建3×3 混淆矩阵
从混淆矩阵中先求解每个类别的某评价的平均值,然后进行平均即得到宏平均值。
将每个类别的 TP 数、FP 数、FN 数、TN 数相加,除以所有数据量,就得到了微平均值。微平均值反映了评估值中数据的百分比
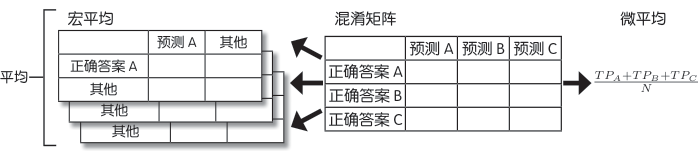
根据任务的不同,有时会重视精确率,有时会重视召回率。如果不是特别重视某一方面的情况,用 F值评价性能比较妥当
一般来说,F值越接近1越好,越接近0效果越差
使用Python进行评价
还是一样,先加载所要使用的库
一口气把上面学到的全部评估一下吧!
from sklearn.datasets import load_diabetes,load_breast_cancer
from sklearn.linear_model import LinearRegression, Ridge, Lasso, LogisticRegression
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisionTreeClassifier接着,创建矩阵
# Load the data
diabetes = load_diabetes()
breast_cancer = load_breast_cancer()
Xb = breast_cancer.data
yb = breast_cancer.target
Xd = diabetes.data
yd = diabetes.target制作分类实例
lineartest = LinearRegression()
ridgetest = Ridge(alpha=20.0)
lassotest = Lasso(alpha=1.0)
logistictest = LogisticRegression(max_iter=3000)
dttest = DecisionTreeClassifier(max_depth=2)下面就来到我们的评估了
lineartestMSE = cross_val_score(lineartest, Xd, yd, cv=5,scoring='neg_mean_squared_error')
ridgetestMSE = cross_val_score(ridgetest, Xd, yd, cv=5,scoring='neg_mean_squared_error')
lassotestMSE = cross_val_score(lassotest, Xd, yd, cv=5,scoring='neg_mean_squared_error')
logistictestF = cross_val_score(logistictest, Xb, yb, cv=5, scoring="f1")
dttestF = cross_val_score(dttest, Xb, yb, cv=5, scoring="f1")一般地,线性回归任务常用均方误差(MSE)进行评估,逻辑回归任务常用F值进行评估
这里只列出使用交叉检验(cross_val_score)和MSE与F值进行评估,其他的自行摸索指标和评分:量化预测的质量-scikit-learn中文社区
cv参数代表折数
sklearn 中的参数 scoring下,均方误差作为评判标准时,是计算的”负均方误差“(neg_mean_squared_error)。这是因为sklearn在计算模型评估指标的时候,会考虑指标本身的性质,均方误差本身是一种误差,所以被sklearn划分为模型的一种损失(loss)。在sklearn当中,所有的损失都使用负数表示,因此均方误差也被显示为负数了。真正的均方误差 MSE 的数值,其实就是 neg_mean_squared_error 去掉负号的数字。
输出我们的评估值
print("Linear Regression MSE: ", -lineartestMSE.mean())
print("Ridge Regression MSE: ", -ridgetestMSE.mean())
print("Lasso Regression MSE: ", -lassotestMSE.mean())
print("Logistic Regression F: ", logistictestF.mean())
print("Decision Tree F: ", dttestF.mean())可以看到,我们的正则化狠狠地把误差翻了近一倍,这就需要我们回到制作分类实例环节调节参数重新评估
深度学习
神经网络
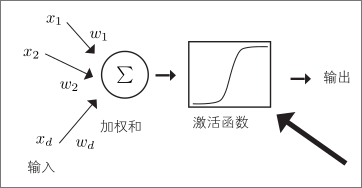
神经网络的基本计算机制是将生物神经细胞的作用置换成简单的模型
生物信息处理如图所示,被称为神经元的神经细胞通过被称为突触的连接部位,形成一个相互连接的复杂网络
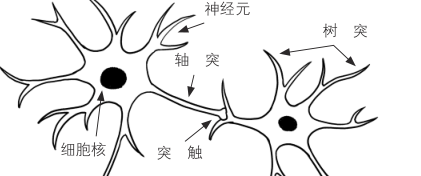
每个神经元接收与其连接的神经元出来的电信号进行正负加权后的信号
加权和达到一定值后自己也会发出电信号
这种神经元的运动可以用图示的阈值逻辑单元来建模
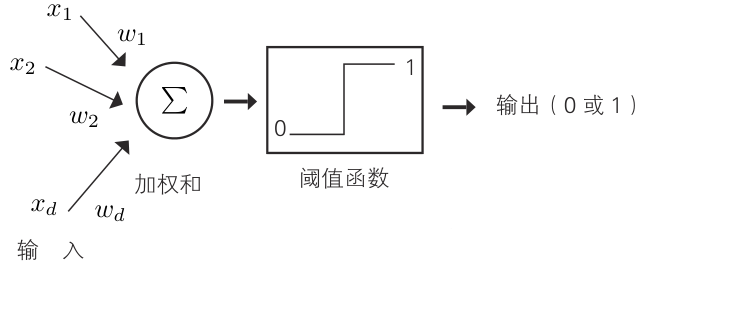
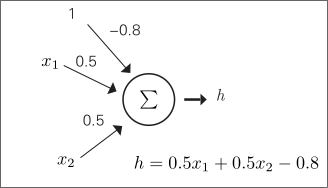
根据输入的加权和 h 确定输出的函数 f (h )通常被称为激活函数
我们可以把神经元看作一个函数
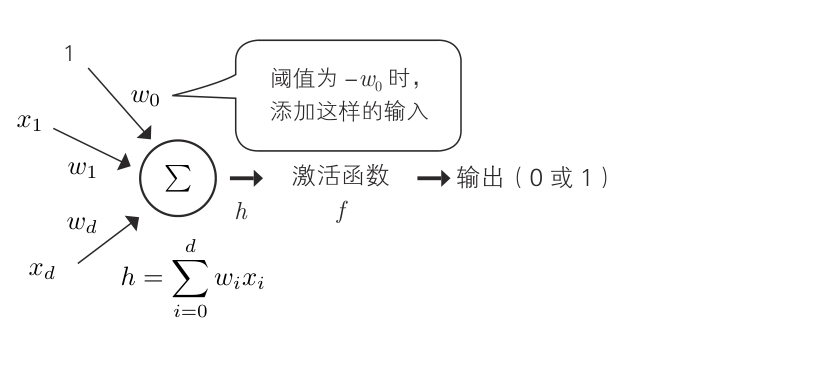
阈值为 -w0,输入端加上值始终为 w0 的输入,可以使用根据加权和的正负输出 1 或0 的简单激活函数
将这些单元分层连接起来就是神经网络。学习时需要激活函数进行微分,但阈值函数是不能微分的,所以通过分层组合单元构成神经网络时,常使用类似于阈值函数的 Sigmoid 函数作为激活函数。(事实上另一种激活函数ReLU函数在很多模型中更高效)
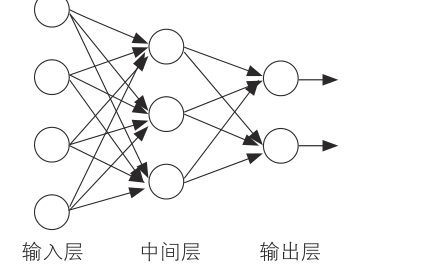
这种形式被称为前馈型神经网络
每个单元只连接相邻层,没有反馈回输入端,所以信号只有从输入到输出这一个方向
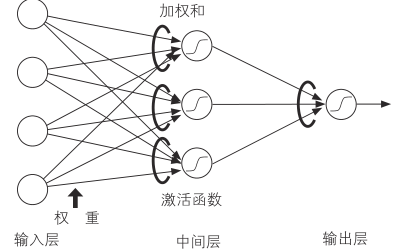
如果把这种连接比作生物机制,那么输入层是接收外界信息的细胞,如感觉细胞。中间层是向脑传达信号的细胞,输出层相当于识别分类的脑细胞
输入层直接输出输入信号,信号被加权后传递到中间层。中间层计算多个输入层传来的信号的加权和,并将激活函数应用于该值,决定中间层的输出
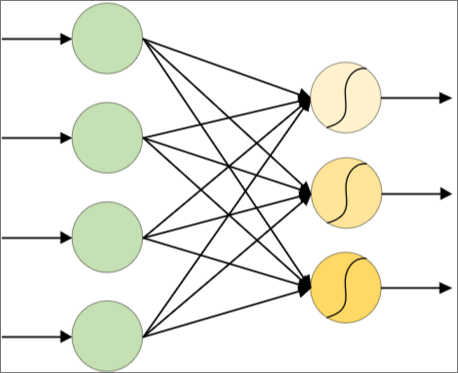
在前馈型神经网络中,制作二值分类问题的分类器时,输出层只有 1 个单元。与逻辑分类相同,输出层的输出值被视为输入为正例的概率
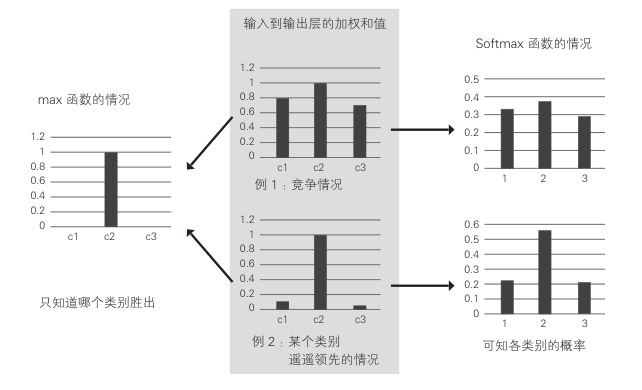
另外,对于多类别分类,输出层的单元数与类别数 c 一致时,多个输出层可能会输出接近 1 的值
在这种情况下,可以使用下述 Softmax 函数代替 Sigmoid 函数作为激活函数 f(h)
其中,hk 为对应类别 k 输出层单元的中间层的输出加权和
将Softmax函数用作激活函数时,各个输出层单元的输出 gk 的总和为 1,可以视为概率
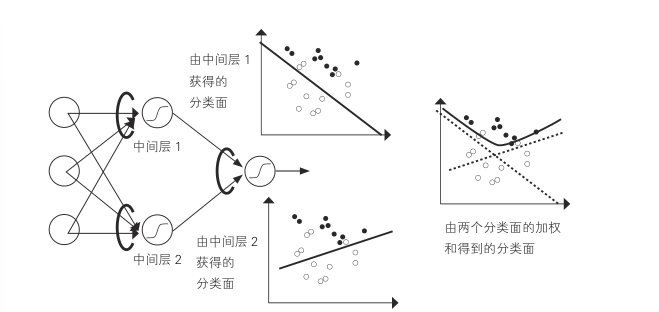
误差反向传播法
通过前馈型神经网络的“学习”就是根据给定数据调整单元组合的权重
每个单元都使用 Sigmoid 函数进行非线性变换,利用结果的加权和,可以得到特征空间中的非线性分类面
为了使非线性分类面的分类误差最小化,就像调整结合权重之前的分类,寻找分类面,使误差最小化
从中间层到输出层的权重的调整,可以通过比较网络输出和监督信号(即正确答案)进行误差评价来学习
误差反向传播法便是一种在中间层没有监督信号,无法与误差进行比较的情况下学习分层网络权重的方法
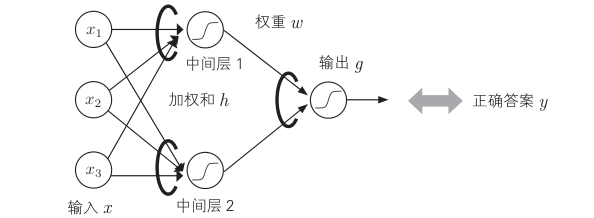
用于训练的一对数据是特征向量 x 和正确答案 y。 令此数据集为 D,其中的第 i 对为(xi,yi)。可以为误差函数设置各种函数,但是在这里我们考虑最小化平方误差的以下函数:
这里,g是输出,w 是神经网络的权重集。下面使用最陡梯度法,着眼于 w 中的特定权重 w,说明调整该值来减小误差的方法。
这里我们只对某一层作计算,在最陡梯度法中,误差函数E(w)用 w 偏微分。此时,权重 w 的变化导致加权和 h 发生变化,进而通过激活函数使输出 g 发生变化。因此,使用合成微分公式可以得到下式 :
如果计算式(3)的右边第 2 项,则根据加权和 h 的定义,可以得到以对象加权 w 连接的前一层的输出。右边第 1 项还可以利用合成微分公式表示如下(为了便于以后使用,把它记为误差量 ϵ ):
式(4)右边第 2 项是激活函数的微分。 由于使用 Sigmoid 函数作为激活函数,因此在这种情况下为g(1 − g)。
右边第一项根据权重的位置进行分类。如果 w 是从中间层到输出层的权重,则右边第一项是误差函数的微分。
另一方面,如果 w 是从输入层到中间层的权重,则右侧第一项中的 g 是中间层的输出,其值会通过输出层的 h 影响输出层的输出。通常,考虑到存在多个输出层,并且 hj 是第 j个输出层的输入,式(4)右侧第一项如下 :
在此,使用式(4)定义的 ϵ 。此方法的要点是, ϵj 是从中间层到输出层的第 j 个连
接的权重,用于从输入层到中间层的权重的校正。综上,误差量 ϵ 的计算如下 :
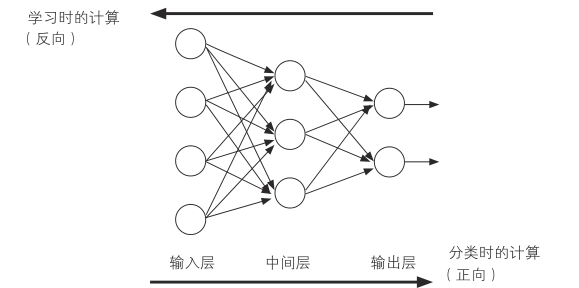
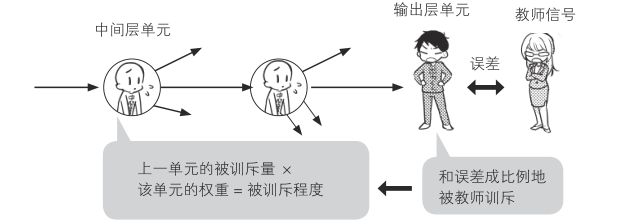
如图中箭头所示,数据分类时的计算是按照输入层、中间层、输出层的顺序进行的,训练时的方向正好相反
输出层的输出和输出信号与教师信号(监督信号)的误差成比例,给人一种被教师训斥的印象
接下来,输出层根据被训斥量和单元权重将训斥传递到中间层
这就是误差反向传播法
多层神经网络
多层神经网络的好处是特征提取也可以作为学习对象
有了深度神经网络,可以直接输入图像数据和声音信号,从单纯的特征表现中逐步提取出复杂的结构,实现非常高的性能
在 20 世纪 80 年代后期,利用误差反向传播法的学习也很流行,尝试通过深度神经网络来提高性能,但是不太顺利
接下来会讲解,说明深度神经网络的问题。
梯度消失问题
深度神经网络如下图所示,通过将前馈型网络的中间层多层化,以提升性能或适用性
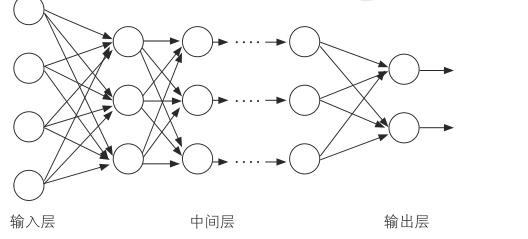
然而,利用误差反向传播法进行多层网络学习面临着梯度消失问题,其中权重校正量会随着其返回层而减小,无法按预期提升性能
在计算误差变化的公式中,必须在每个阶段用 Sigmoid 函数的微分 :
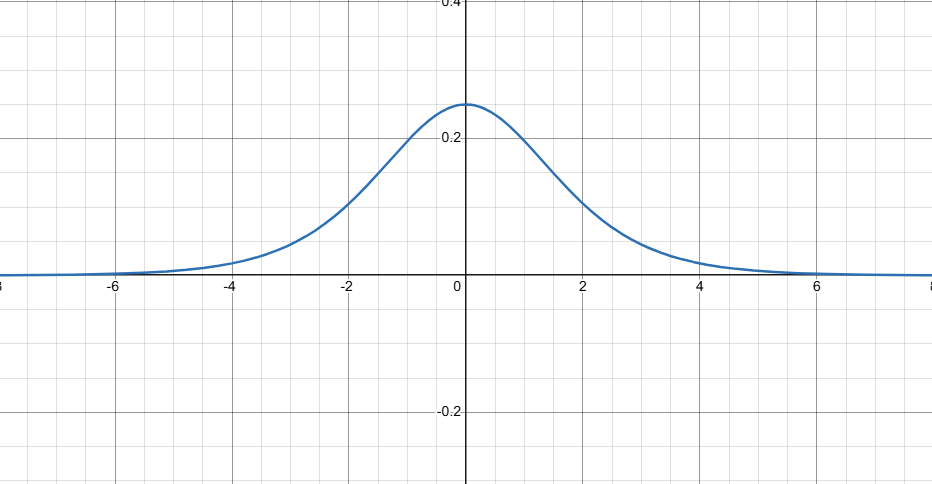
这是这个值的图像
梯度最大为 0.25
相对较大值仅限于单元输入 =0 附近,也就是说,梯度在多数情况下都接近 0,那样的话,学习就无法继续了
该问题的解决思想分为两种 :
① 在多层学习上下工夫
② 导入针对问题的结构
下面介绍两种解决办法
①预训练法
随着输入层的提高,节点(单元)数会减少,如果不能很好地提取特征的话,信息就无法保持
保留原始信息、持续获得高抽象度信息表示的预训练法,是梯度消失问题的解决方法
所谓预训练法,就是在利用误差反向传播法进行学习之前,用某种方法事先调整好权重的初始参数
那么,预先调整输入层和下一个相邻输入层的权重
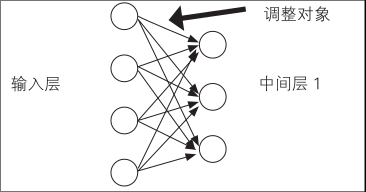
这里的权重只要能将高维输入转换成有助于识别的低维表示就可以了
从而把问题转换成“用更少的单元数尽可能地压缩特征向量的信息”
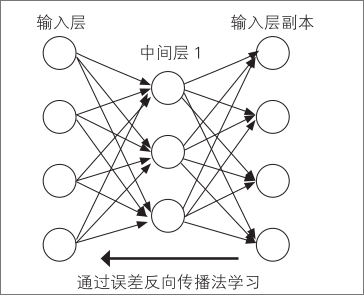
首先,在中间层复制输入层单元,作为输出层。然后,进行在输出层再现输入层信息的学习。这被称为自动编码器
一般来说,中间层单元数设定得比输入层单元数少,所以不能将输入层信息原样复制到输出层
因此,中间层被赋予了“获得更低维压缩的信息”这样的重任
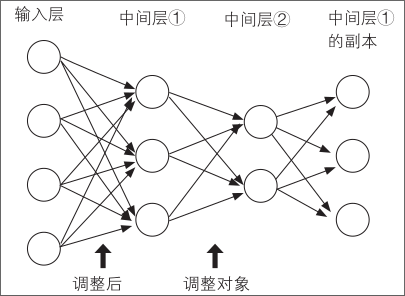
这样,调整输入层和中间层①的权重后固定,然后在中间层①和中间层②之间进行同样的学习,重复操作到输出层,就能够提取重要性高的特征
②调整激活函数
着眼于由输入的加权和来决定输出的激活函数,也是一种办法
不使用之前说过的 Sigmoid 函数,而使用 Rectified Linear 函数,f (x) = max(0, x)作为激活函数。该函数使用的单元被称为 ReLU(Rectified Linear Unit)
对于 Rectified Linear 函数,当输入参数小于 0 时,输出为 0 ;当输入参数大于等于 0 时,输出其值
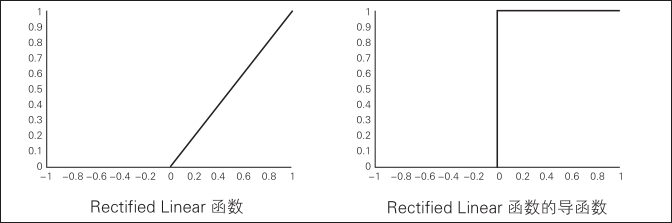
使用 ReLU 时,半个区域的坡度是 1,所以误差不会消失
对于其他许多单元输出为 0 的稀疏网络,可以高速执行梯度计算,无需预训练即可完成学习
过拟合(过学习)问题
与之相对地还有欠拟合,也就是训练不足,根本没学会,这里不作讨论
拥有大量参数的模型,很容易过度适应训练数据
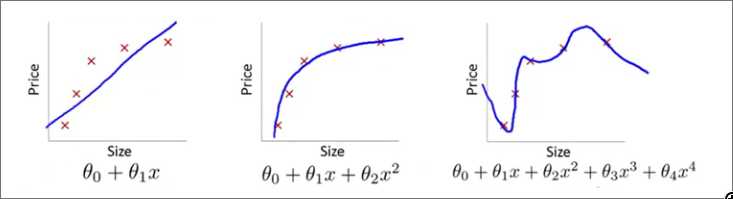
左为欠拟合,中为理想模型,右为过拟合
有报告指出,作为过度学习的对策,使用 Dropout 方法可以防止过学习,提高通用性
Dropout 是随机丢弃一定比例的单元进行学习
首先,以百分比 p 随机禁用每层的单元
如令 p = 0.5,可以得到由半个单元组成的神经网络
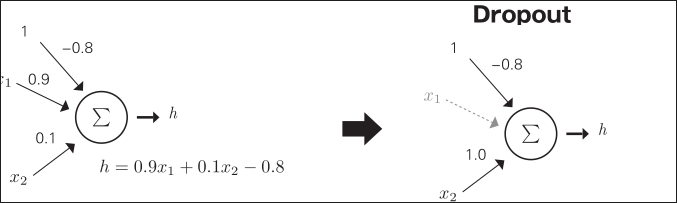
x1 和 x2 都是重要信息,但由于学习时的初始值存在细微差异,学习结果的权重会有很大差异
未知数据中 x1 的值稍微变小,也有可能导致分类错误
学习时输入会以一定的概率丢弃,因此要使权重值保持一致,以便选出正确答案
这样使未知数据中输入值有一些变化也能尽量接近正确答案
使用学习后获得的神经网络进行分类时,将权重乘以 p,也就是对多个学习过的网络的计算结果求平均
对与Dropout预防过学习的原因,有一种理论认为,减小自由度和正则化有相同的作用 ;还有一种理论认为,即使学习进行了,梯度也保持不变,这是因为输入到节点的加权和 h 的方差增大了
研究者们众说纷纭,但无论如何还是避免了将相同数据重复输入到具有相同结构的网络中的情况,或者说过度依赖某些神经元的问题,因此不太可能发生过学习
具有特殊结构的神经网络
到目前为止,我们讨论了解决多层学习问题的方法,接下来说明实现学习的另一种方法
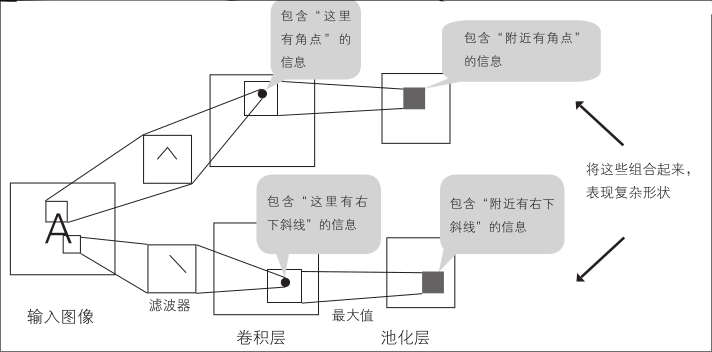
这是一种将网络结构特殊化为任务的方法。专门针对任务的深度神经网络代表是图像识别中常用的卷积神经网络(CNN)
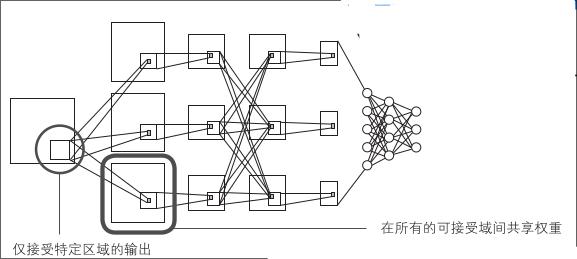
在卷积神经网络中,单元之间的连接数小于简单完全连接网络的连接数,因为特定单仅接收上一层特定区域的输出
另外,各卷积层对所有的接受域都共享权重,所以应该学习的参数大幅减少。进而构成了可以直接输入图像的多层神经网络,特征提取处理也成了学习对象
如下图所示,交替配置卷积层和池化层,通常将接受最后的池化层输出的神经网络配置在最终输出侧,另外在较复杂的任务中通常会在两者之间夹带一个激活函数层,以赋予模型更强大的非线性处理能力。
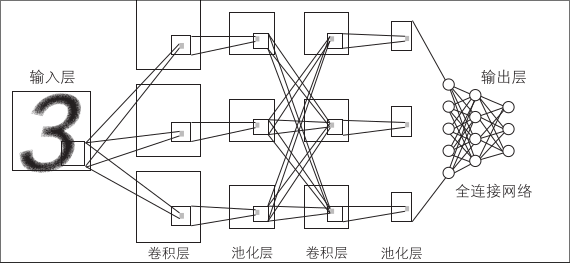
其中,全连接层负责把数据集中起来,综合分析得到结果
卷积层
卷积层的处理相当于对图像进行滤波处理
滤波并提取图像模式的滤波器,如下图右侧所示的 3×3 小图像
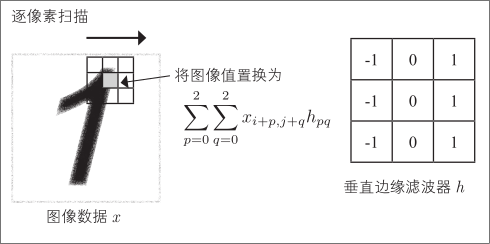
对该图像逐像素扫描,从原始图像中提取图案。这里的边缘滤波器是一个在垂直方向上发生颜色变化时会产生反应的滤波器
例如,假设在 9×9 像素的原始图像上画上单色“垂直线”,用 0 表示白色,用 1 表示黑色
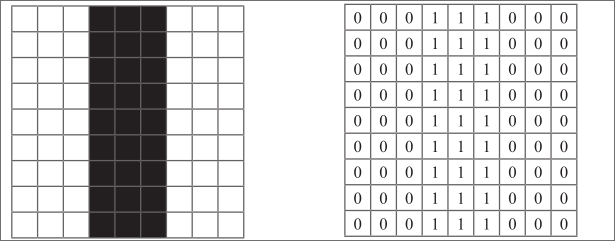
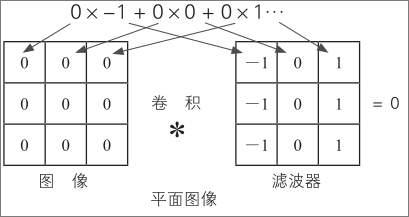
将刚才的滤波器应用于该图像进行图案检测。例如,左端和应用滤波器后的值每次相乘并相加后都为 0
当滤波器垂直方向的中间色变化时
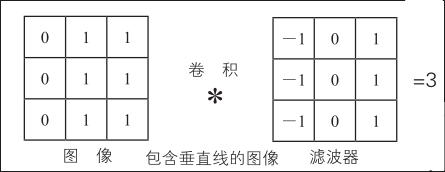
通过这个滤波器后,只有垂直部分有较大的值,即提取了图案
那么,将此垂直边缘滤波器应用于水平方向具有过渡色的图像时结果为0
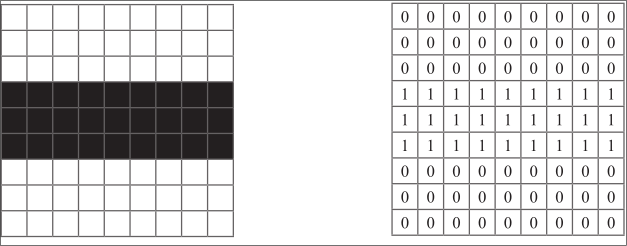
即使水平方向有颜色变化,但因为灰度相同,在右边乘以 1、在左边乘以 -1 后值也是 0。换句话说,该边缘滤波器不能检测水平方向的图案

对于输入图像 A,需要角点检测、水平线检测和斜线检测三种滤波器
卷积层的各单元只与输入图像的一部分连接,权重由所有单元共享。连接范围对应滤波器的大小,该范围被称为接受域
池化层
池化层能够对在卷积层中检测到的特征进行分类和压缩
因为在卷积层中会不可避免的提取出许多不必要的特征,所以有必要压缩筛选出那些有用的特征
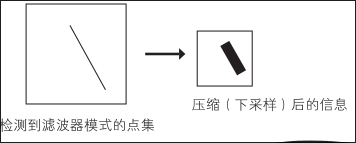
例如,识别手写字母图像时,因为每个人有自己的书写习惯,位置会出现偏差
在池化层,要删除图像的详细信息,努力解决这些偏差
池化层比卷积层包含更少的单元,但每个单元的接受域和卷积层相同
根据每个单元的值输出平均值或最大值,可以吸收接收域中模式的位置变化
使用Python进行数字图像识别
Python 深度学习编程可以使用深度学习库。
这里使用一个名为 Keras 的库。利用 Keras 可以使用流行的深度学习库 Tensor Flow 作为更高层次描述组件,基于简单的代码来编写深度学习的典型问题。
import kerasMNIST是手写数字的灰度图像数据,图像尺寸为28像素×28像素,各像素的灰度值为0~255的整数。
其中包含60 000个用于训练的图像和10 000个用于测试的图像。Keras可以自动下载MINST数据集,并分为训练图像/标签集和测试图像/标签集,然后将其作为numpy数组返回。
from keras import layers
(X_train, y_train), (X_test, y_test) = keras.datasets.mnist.load_data()接下来,让我们稍微加工一下数据集。首先,将输入转换为卷积神经网络的标准输入。
图像识别通常是针对彩色图像的,每个图像是纵向像素数(高)×横向像素数(宽)×颜色通道数的三维张量,整个输入数据表现为在开头加上图像数的四维张量。
这里的灰度图像由图像数×纵向像素数(高)×横向像素数(宽)表示,加上第4个维度的颜色通道数1后,就转换为4维张量。
另外,如果神经网络的输入为0~1这样的小范围,则不需要调整权重的初始值和学习率的比例。这里,像素的最大值为255,所以从整数型转换为浮点型后,所有数据要除以255。这种方法叫归一法
归一法最根本的目的是让模型更快更好的收敛 ,提高稳定性
img_rows, img_cols = 28, 28
X_train = X_train.reshape(X_train.shape[0], img_rows, img_cols, 1)
X_test = X_test.reshape(X_test.shape[0], img_rows, img_cols, 1)
input_shape = (img_rows, img_cols, 1)
X_train = X_train.astype('float32') / 255
X_test = X_test.astype('float32') /255接下来是输出加工。正确答案标签将图像所表示的数字用0~9的整数表示,并转换成被称为one-hot的10维向量。
在one-hot 表达中,只有正确答案的维对应的值为1,剩下的是0。这是因为神经网络的输出层由类别数(这次是10)构成,易转换成作为该输出层监督信号提供的形式。
Y_train = keras.utils.to_categorical(y_train)
Y_test = keras.utils.to_categorical(y_test)下面定义卷积神经网络的结构。重复两次卷积(滤波器大小为3×3)和池化(大小为2×2),然后将输出进行一维排序,并传递到两层神经网络进行分类。激活函数对于输出层是softmax,对于所有其他层是ReLU。
n_out = len(Y_train[0]) # 10
model = Sequential()
model.add(Conv2D(16, kernel_size=(3, 3),
activation='relu',
input_shape=input_shape))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Conv2D(32, (3, 3), activation='relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(Dense(n_out, activation='softmax'))
model.summary()在Keras中,可以使用summary方法查看已建网络的结构。
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 16) 160
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 16) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 32) 4640
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 32) 0
_________________________________________________________________
flatten_1 (Flatten) (None, 800) 0
_________________________________________________________________
dense_1 (Dense) (None, 128) 102528
_________________________________________________________________
dense_2 (Dense) (None, 10) 1290
=================================================================
Total params: 108,618
Trainable params: 108,618
Non-trainable params: 0
_________________________________________________________________对这个网络,用compile 方法给出评价函数categorical cross entropy和优化器RMSProp,然后用fit方法进行学习。
model.compile(loss = 'categorical_crossentropy',
optimizer = 'rmsprop',
metrics = ['accuracy'])
model.fit(X_train, Y_train, epochs=5, batch_size=200)
score = model.evaluate(X_test, Y_test, verbose=0)
print('Test loss:', score[0])
print('Test accuracy:', score[1])下面是输出
Epoch 1/5
60000/60000 [=================] - 13s 224us/step - loss: 0.2883 -
acc: 0.9130
Epoch 2/5
60000/60000 [=================] - 13s 210us/step - loss: 0.0763 -
acc: 0.9765
Epoch 3/5
60000/60000 [=================] - 14s 239us/step - loss: 0.0516 -
acc: 0.9836
Epoch 4/5
60000/60000 [=================] - 14s 238us/step - loss: 0.0384 -
acc: 0.9874
Epoch 5/5
60000/60000 [=================] - 14s 235us/step - loss: 0.0306 -
acc: 0.9906
Test loss: 0.03475515839108266
Test accuracy: 0.9878测试数据的准确率为98.78%,看来性能非常高。
因为MINST中包含了几十个模棱两可,或完全错误的数据,所以准确率不会达到几乎100%
下面是Keras官网给出的代码,试试看能不能自己看懂
import numpy as np
import keras
from keras import layers
# Model / data parameters
num_classes = 10
input_shape = (28, 28, 1)
# Load the data and split it between train and test sets
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
# Scale images to the [0, 1] range
x_train = x_train.astype("float32") / 255
x_test = x_test.astype("float32") / 255
# Make sure images have shape (28, 28, 1)
x_train = np.expand_dims(x_train, -1)
x_test = np.expand_dims(x_test, -1)
print("x_train shape:", x_train.shape)
print(x_train.shape[0], "train samples")
print(x_test.shape[0], "test samples")
# convert class vectors to binary class matrices
y_train = keras.utils.to_categorical(y_train, num_classes)
y_test = keras.utils.to_categorical(y_test, num_classes)
model = keras.Sequential(
[
keras.Input(shape=input_shape),
layers.Conv2D(32, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Conv2D(64, kernel_size=(3, 3), activation="relu"),
layers.MaxPooling2D(pool_size=(2, 2)),
layers.Flatten(),
layers.Dropout(0.5),
layers.Dense(num_classes, activation="softmax"),
]
)
model.summary()
batch_size = 128
epochs = 15
model.compile(loss="categorical_crossentropy", optimizer="adam", metrics=["accuracy"])
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_split=0.1)
score = model.evaluate(x_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test accuracy:", score[1])集成学习
对于语音、图像和自然语言那样特征之间紧密联系的数据,利用深度学习分类十分有效,但对于特征独立,也就是说各特征之间没有联系的数据,则需要根据具体案例分析。
对于数据量较少,数据维数较少且各特征独立的情况下,集成学习具有比深度学习更大的分类能力
集成学习多是线性内容,结构较简单,所以可解释性较强,也就是让别人信服和及时发现错误的能力较强
集成学习的灵活性很高,可以与深度学习相结合,这种结合可以充分利用两者的优势
集成学习提高性能的方法便是组合多个较弱的分类器,整合结果
在集成学习中,最重要的是如何制作独立的分类器。如果三个人的回答基本一致的话,性能和一个人给出答案的情况就没有区别
接下来介绍在集成学习中,制作出尽可能不同的分类器的3 种方法
分类器的算法
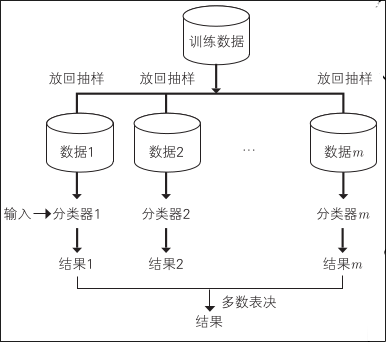
Bagging 算法
Bagging 是从训练数据中放回抽样与数据大小相同的独立数据集合,并为每个数据集创建具有相同算法的分类器
放回抽样是记录提取的数据后再恢复原状的抽样方法,也就是无论抽多少次,每个数据被抽到的概率相同。这种方法可以多次提取相同的数据,但是某些数据可能一次都不会被抽样
试着估算一下,通过放回抽样制作的数据集和原来的数据集有多大不同
数据集合的元素数为 N。如果着眼于某个特定的数据,那么在一次抽样中没有被选中的概率是多少?
假设有 N 个数据,某个数据被选中的概率为 1/N ,则没有被选中的概率为 1 − 1/N
在 N 次放回抽样中,这个数据一直没有被选中的概率为
这就是某个数据不包含在放回抽样的某个数据集中的概率。
当N = 10 时,概率为 0.349 ;
当N = 100 时,概率为 0.366 ;
当N → ∞时,概率为 1/e =0.368。
不管 N 取何值,概率都没什么变化。
从该计算来看,对于任何取值的 N,放回抽样后的数据集中,不包含原数据集中约 1/3 的数据。
对与使用哪种机器训练方法来创建分类器
原理上哪种都行,但是创建分类器的算法不稳定,最好选择对训练数据差异比较敏感的算法
比如决策树,只要数据稍有不同就会变成不同的分类器
每个分类器都以相同的训练数据量学习,所有分类器都同样可信,结果的整合简单地采用多数表决方式
随机森林
随机森林(Random Forest)是一种在Bagging 的基础上创建不同分类器的算法
与Bagging有一点是相同的,都是对训练数据进行放回抽样,制作多个大小相同的数据集
不同点在于在选择节点的分支特征时,从所有特征中选出预定数量的特征,从中选出分担能力最高的特征
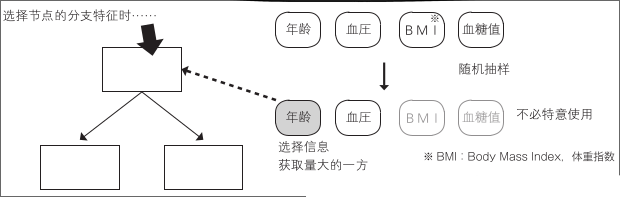
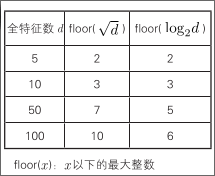
当全特征数为 d 时,选择特征的数量通常为 √d 或 log_2 d
并且该操作在叶子变成单一类集合之前递归执行
也就是说在选取特征时,会随机选取一部分特征进行考虑,这样提高了分类器的多样性
正如随机森林的名字一样,随机森林的算法基于决策树的特性,所以一般不使用其他训练方法
在随机森林中,要故意过拟合,以尽可能创建不同的树
为什么呢?在随机森林中要尽量提高分类器的多样性,这就需要尽量提高不稳定性,且多个分类器的过拟合相互抵消,反而提高了模型的泛化能力
下面讲解如何由随机森林创建单个树
例如,假设有 5 种训练数据 A ~ E
确定根节点的分支特征时,从这里开始预定数量,如随机选择 3 种类型
假设这里选择 A、B、E
计算各自的分类能力,选择分类能力最高,也就是信息量最大的属性,根据该值分割数据

对于分割的数据集,同样随机选择属性集,选择其中分类能力最高的属性来生长树
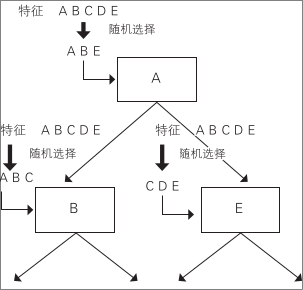
这样做的话,利用同样的数据也能创建出不同的决策树
Boosting 算法
Bagging 和随机森林通过改变使用的数据集、改变构成分类器的条件,创建不同的分类器
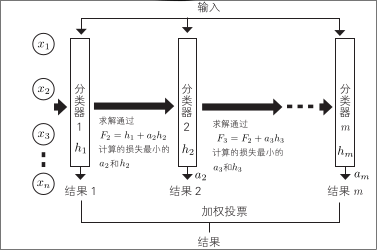
与之相对应的是,Boosting(提升)算法通过不断添加专门用于减少错误的分类器,创建不同行为的分类器集合
为此,要为各个数据设置权重
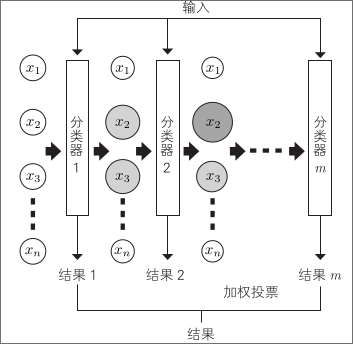
起初使用具有平等权重的训练数据创建分类器。对于该分类器错误分类的数据,增加其权重
调整权重,使正确分类数据的权重之和与错误分类数据的权重之和相等
就像你在组织一个知识竞赛,每个队员都回答了一些问题,但有些问题被错误回答了。为了提高整体的正确率,你会让队员们在下一轮中重点复习那些错误的问题。这样,队员们在下一轮中就能更好地回答这些问题,从而提高整体的正确率。
通过为权重变化后的数据集学习下一个分类器来逐步创建不同的分类器
稍后创建的分类器会优先分类前一个分类器错误分类的数据,它与前一个分类器不同,可以弥补其缺点
这种训练方法便是 AdaBoost 算法
用于 Boosting 的分类器的训练算法需要采用以权重为基础创建分类器的数据
Boosting 算法,是专门针对前面的错误,按顺序创建分类器,也就是说,原始训练数据是失真的。对于未知输入,其可靠性和忠实于原始训练数据的分类器不同
所以通过针对各分类器,计算基于误差函数值的权重,用加权投票得出分类结果,这与Bagging算法的求平均与多数投票是不同的
利用 Boosting 结果产生的复合分类器可以定义损失函数
因此,添加的分类器也可以选择尽量减小损失函数值的方式
按照该思路进行提升的方法被称为梯度提升法
使用Python实现集成学习
使用机器学习工具 Weka 附带的 diabetes.arff 数据。它很接近糖尿病诊断网站的需要。
scikit-learn 也有同名的数据集,这是回归问题用的数据集,因为结果的解释有点难,所以使用分类问题数据集 diabetes.arff。
diabetes.arff 是根据几个检查结果预测得到的糖尿病诊断结果,特征有年龄、血压、BMI 等。
请提前下载好 diabetes.arff。
可以从 https://github.com/bnjmn/weka/blob/master/wekadocs/data/diabetes.arff
下载数据集,但是用这个文件名也很容易搜索到。
import numpy as np
from scipy.io import arff
from sklearn.ensemble import BaggingClassifier, RandomForestClassifier,
AdaBoostClassifier, GradientBoostingClassifier
from sklearn.model_selection import cross_val_score使用 scipy 的 arff 模块读取 arff 格式的文件。因为特征向量和正确答案标签排列在一行中,因此请将它们保存在不同的 numby 数组中。
data, meta = arff.loadarff('diabetes.arff')
X = np.empty((0,8), dtype=float)
y = np.empty((0,1), dtype=np.str)
for e in data:
e2 = list(e)
X = np.append(X, [e2[0:8]], axis=0)
y = np.append(y, e2[8:9])使用 scikit-learn 的话,集成学习也可以和之前的分类器按同样的步骤进行训练和测试。用 10-folder 交叉验证法,预先确认精度的均值和方差。
clf1 = BaggingClassifier()
scores = cross_val_score(clf1, X, y, cv=10)
print("{0:4.2f} +/- {1:4.2f} %".format(scores.mean() * 100, scores.std() * 100))
clf2 = RandomForestClassifier()
scores = cross_val_score(clf2, X, y, cv=10)
print("{0:4.2f} +/- {1:4.2f} %".format(scores.mean() * 100, scores.std() * 100))
clf3 = AdaBoostClassifier()
scores = cross_val_score(clf3, X, y, cv=10)
print("{0:4.2f} +/- {1:4.2f} %".format(scores.mean() * 100, scores.std() * 100))
clf4 = GradientBoostingClassifier()
scores = cross_val_score(clf4, X, y, cv=10)
print("{0:4.2f} +/- {1:4.2f} %".format(scores.mean() * 100, scores.std() * 100))
对于默认参数,梯度提升会得到更好的结果。



